 Ayingotts's notes
Ayingotts's notes内存:值放堆上还是放栈上
内存
let s = "hello world".to_string();let s = "hello world".to_string();上面的这条语句,跟只读数据段 ( RODATA ) 、堆、栈分别有深度交互:
hello world作为字符串常量 ( string literal ),在编译时被存入可执行文件的.RODATA段 ( GCC ) 或.RDATA段 ( VC++ ),在程序加载时,获得一个固定的内存地址- 执行
"hello world".to_string()时,在堆上,一块新的内存被分配出来,并把hello world逐个字节拷贝过去 - 当把堆上的数据复制给
s时,s作为分配在栈上的一个变量,它需要知道堆上内存的地址;由于堆上的数据大小不确定且可以增长,还需要知道它的长度以及它现在有多大
最终,为了表述这个字符串,使用了三个 word:
- 表示指针
- 表示字符串的当前长度 ( 11 )
- 表示这片内存的总容量 ( 11 )
在 64 位系统下,三个 word 是 24 字节。
栈
栈是程序运行的基础。每当一个函数被调用时,一块连续的内存就会在栈顶被分配出来,这块内存被成为帧 ( frame ) 。
栈自顶向下增长。一个程序的调用栈最底部,除去入口帧 ( entry frame ) ,就是 main() 函数对应的帧,随着 main() 函数的一层层调用,栈会一层层扩展;调用结束,栈会一层层回溯,释放内存。
调用过程中,一个新的帧会分配足够的空间存储寄存器的上下文。在函数里使用到的通用寄存器会在栈保存一个副本,当函数调用结束,通过副本,可以恢复原本的寄存器的上下文。函数所需要使用到的局部变量,也都会在帧分配的时候被预留。
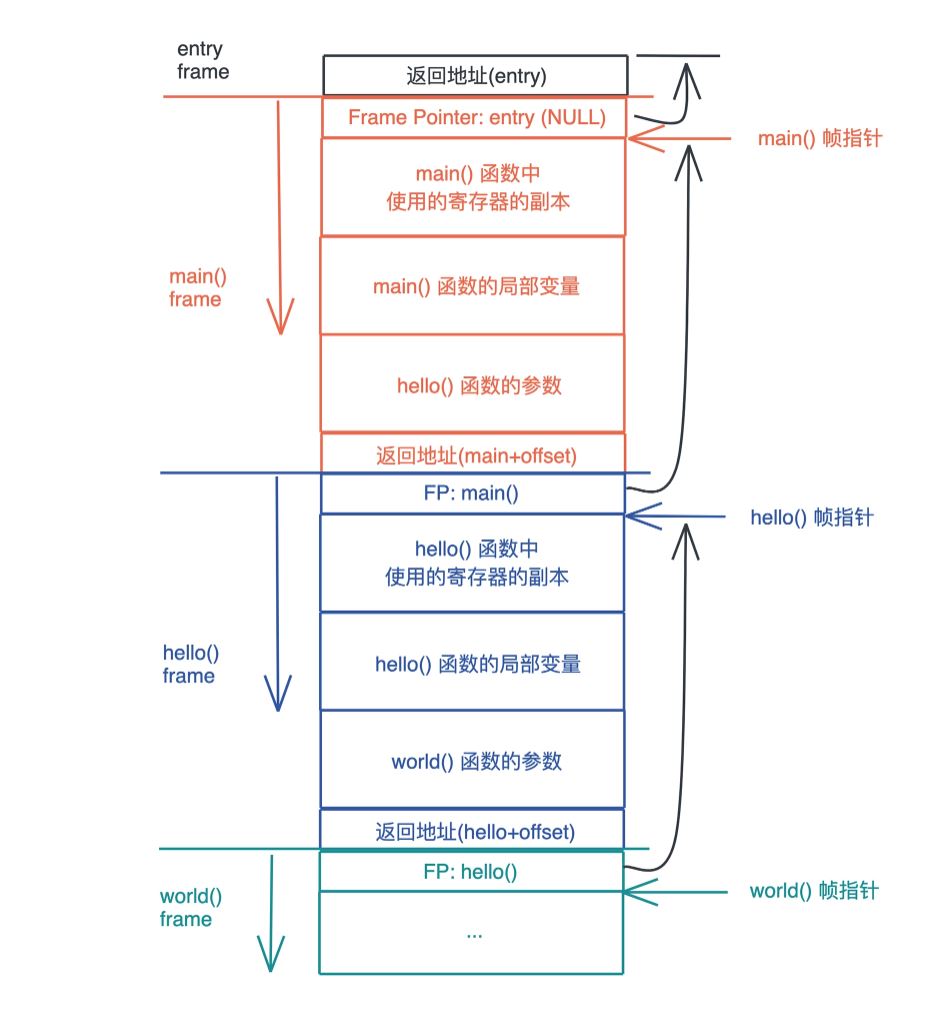
函数运行时,如何确定需要多大的帧呢?
归功于编译器,在编译并优化代码的时候,一个函数就是一个最小的编译单元。
在这个函数里,编译器得知道用到哪些寄存器、栈上要放哪些局部变量,这些都在编译时确定。所以编译器需要明确每个局部变量的大小,以便于预留空间。
所以:在编译时,一切无法确定大小或者大小可以改变的数据,都无法安全地放在栈上,最好放在堆上。
例如:
fn say_name(name: String) {}
// 调用
say_name("zhangsan".to_string());
say_name("lisi".to_string());fn say_name(name: String) {}
// 调用
say_name("zhangsan".to_string());
say_name("lisi".to_string());函数的参数是字符串时,在编译时大小不确定,运行时执行到具体的代码才知道大小。
所以,无法把字符串本身放在栈上,只能先将其放在堆上,然后在栈上分配对应的指针,引用堆上的内存。
但参数类型是数值类型,如 int 时,无论参数是什么值,占用内存都是固定的。
栈溢出
栈上的内存分配是非常高效的。
栈空间的调整是通过移动栈指针实现的。
只要改动栈指针 ( stack pointer ),就可以预留相应的空间;改回栈指针,预留的空间又会被释放。预留和释放只是动动寄存器,不涉及额外计算、不涉及系统调用,所以效率很高。
理论上,把变量分配到栈上,可以获得更好的运行速度。但实际上,需要避免把大量的数据分配在栈上。
原因是考虑到调用栈的大小,避免栈溢出 ( stack overflow )。
一旦当前程序的调用栈超出了系统允许的最大栈空间,无法创建新的帧来运行下一个要执行的函数,就会发生栈溢出,这时程序会被系统终止,产生崩溃信息。
过大的栈内存分配是导致栈溢出的原因之一,更多的原因是递归函数没有妥善终止。一个递归函数不断调用自己,每次调用都会形成一个新的帧,如果递归函数无法终止,最终就会导致栈溢出。
堆
当需要动态大小的内存时,只能使用堆,比如可变长度的数组、列表、哈希表、字典,它们都分配在堆上。
最佳实践:堆上分配内存时,预留一些空间。
例如,创建一个列表,并添加两个值:
let mut arr = Vec::new();
arr.push(1);
arr.push(2);let mut arr = Vec::new();
arr.push(1);
arr.push(2);这个列表实际预留的大小是 4 ,并不是其长度 2 。因为堆上内存分配会使用 libc 提供的 malloc() 函数,其内部会请求操作系统的系统调用,进行内存分配。系统调用的代价是昂贵的,所以要避免频繁地 malloc() 。
如果每次只分配需要的内存,当列表新增值时,需要:
- 分配更大的新内存
- 拷贝已有数据
- 添加新值
- 释放旧内存
这样操作的效率很低。所以堆内存分配时,预留的空间大小会大于实际需要的大小。
除了动态大小的内存需要被分配到堆上,动态生命周期的内存也需要分配到堆上。
栈上的内存在函数调用结束之后,所使用的帧被回收,相关变量对应的内存也都被回收待用。所以栈上内存的生命周期是不受开发者控制的,并且局限在当前调用栈。
而堆上分配出来的每一块内存都需要显式地释放,这就使堆上内存有更加灵活的生命周期,可以在不同的调用栈之间共享数据。
内存泄露
手工管理堆内存,分配后忘记释放,会造成内存泄漏。一旦内存泄漏,程序运行得越久,内存占用就越大,最终会因为占满内存而被操作系统终止运行。
堆越界
如果堆上内存被多个线程的调用栈引用,该内存的改动要特别小心,需要加锁独占访问,以避免潜在的问题。比如,一个线程在遍历列表,而另一个线程在释放列表中的某一项,就可能访问野指针,导致堆越界 ( heap out of bounds ) 。堆越界是第一大内存安全问题。
使用已释放内存
如果堆上内存被释放,但栈上指向堆上内存的相应指针没有被清空,就有可能发生使用已释放内存 ( use after free ) 的情况,程序轻则崩溃,重则隐含安全隐患。使用已释放内存是第二大内存安全问题。
GC、ARC
为了避免内存手动管理造成的问题
- Java 等语言采用追踪式垃圾回收 ( Tracing GC ) 的方式,自动管理内存。这种方式通过定期标记 ( mark ) 找出不再被引用的对象,然后将其清理 ( sweep ) 掉,来自动管理内存,减轻开发者负担。
- ObjC 和 Swift 采用自动引用计数 ( Automatic Reference Counting ) 的方式。在编译时,它为每个函数插入
retain / release语句来自动维护堆上对象的引用计数,当引用计数为零时,release 语句就释放对象。
对比:
- GC 在内存分配和释放上无需额外操作,而 ARC 添加了大量的额外代码处理引用计数。所以 GC 效率更高,吞吐量 ( throughput ) 更大。
- GC 释放内存的时机是不确定的,释放时引发的 STW ( Stop The World ) ,也会导致代码执行的延迟 ( latency ) 不确定。所以一般携带 GC 的编程语言,不适合做嵌入式系统或实时系统。但是,Erlang VM 是个例外,它把 GC 的粒度下放到每个 process,最大程度解决了 STW 的问题。
上述的 GC 性能和通常所说的性能,含义并不相同。常说的性能是吞吐量和延迟的总体感知,和实际性能是有差异的,GC 和 ARC 就是典型例子。GC 分配和释放内存的效率和吞吐量要比 ARC 高,但因为偶尔的高延迟,导致被感知的性能比较差,所以会给人一种 GC 不如 ARC 性能好的感觉。
小结
回顾基础概念,分析了栈和堆的特点。
对于存入栈上的值,它的大小在编译期就需要确定。栈上存储的变量生命周期在当前调用栈的作用域内,无法跨调用栈引用。
堆可以存入大小未知或者动态伸缩的数据类型。堆上存储的变量,其生命周期从分配后开始,一直到释放时才结束,因此堆上的变量允许在多个调用栈之间引用。但也导致堆变量的管理非常复杂,手工管理会引发很多内存安全性问题,而自动管理,无论是 GC 还是 ARC ,都有性能损耗和其它问题。
总结:
- 栈上存放的数据是静态的,固定大小,固定生命周期
- 堆上存放的数据是动态的,不固定大小,不固定生命周期
思考题
如果有一个数据结构需要在多个线程中访问,可以把它放在栈上吗?为什么?
答:不能,栈上的数据会随着当前线程的函数调用栈销毁而回收。
补充:在多线程场景下,每个线程的生命周期是不固定的,无法在编译期知道谁先结束谁后结束,所以不能把属于某个线程 A 调用栈上的内存共享给线程 B,因为 A 可能先于 B 结束。这时候,只能使用堆内存。这里有个例外,如果结束的顺序是确定的,那么可以共享,比如 scoped thread 。
可以使用指针引用栈上的某个变量吗?如果可以,在什么情况下可以这么做?
答:可以,在当前函数调用栈中,可以新建变量在栈上开辟,顺便分配一个指针指向它,但是注意,这个指针的生命周期只能在当前栈帧中,不能作为返回值给别人用。
补充:同一个调用栈下,
main()调用hello(),再调用world(),编译器很清楚,world()会先结束,之后是hello(),最后是main()。所以在world()下用指针引用hello()或者main()内部的变量没有问题,这个指针必然先于它指向的值结束。
这两个问题的实质是要搞明白哪些东西在编译期可以确定它们的关系或者因果,哪些只能在运行期确定。